作者:高士峰、曾俊翰、林惠勇
在自動駕駛技術越來越成熟的情況下,自駕車的服務也逐漸擴展到公共交通運輸上,目前國內外對這個應用皆投入相當大的資源進行研發。國內也能看到一些自駕交通工具的雛形,例如車輛測試中心(ARTC) 聯合多家廠商,針對自駕接駁運輸所開發的科專計劃平台車、台中市政府、鼎漢工程顧問、豐榮客運、工研院機械所、緯創資通及台數科等公司所合作的水湳自駕巴士還有台北市政府與台灣智駕等公司合作的台北市信義路公車專用道自駕巴士創新實驗計畫等。
在自駕公車應用逐漸發展下,我們將考慮到搭乘自駕公車的乘坐品質,例如乘客的搭乘狀況,依個別乘客給予特定的需求。像是當系統偵測到乘客站立或者站起來時,自駕系統能自動將行車速度作適度的調整,以降低乘客跌倒的機率,讓自駕公車所提供的服務更加全面性;而在非自駕車的情況下我們仍然可以考慮到公車乘客服務品質,例如有時候司機因專注於路況而沒有及時了解乘客需求,若透過車載系統進行辨識,將使乘客有更佳的乘車體驗。
動作辨識在電腦視覺領域上一直以來都是熱門的研究項目,利用動作辨識我們可以得知影像中的人正在進行什麼行為,應用上的例子像是利用公共攝影機分析人的動作,只要有危險的行為就可以即時紀錄或是報警,以大幅加強公共安全。
本文將透過車廂內部的攝影機,進行車廂內乘客偵測,包括乘客數量、乘客姿態與乘客動作辨識,藉由車廂內的攝影機達到即時監控的效果。
乘客偵測
本文的研究系統架構主要分三個部分。第一個部分為人的偵測器,提供畫面中人的定位資訊,在偵測器上本文使用YOLOv3[1],YOLOv3在偵測人上有不錯的效果,且相比其它架構像是Faster R-CNN的實時性更高。第二部分為動作辨識,本研究參考[2]提出的Action Tube觀念,透過偵測器進行人的定位後再藉由關聯演算法追蹤畫面中的人。需要追蹤的原因為在相機畫面中,並非只會出現單一個人,因此有必要獲取每個人的位置資訊並依此裁切感興趣區域,裁切後再將每個人在不同時間的畫面串聯成一個序列,做為第二階段動作分類的輸入。系統流程如圖1,在輸入圖片後會經過YOLOv3進行人的偵測,偵測到畫面中的每一個人後,沿著時間軸對每個人進行追蹤,儲存每個人的畫面資料,並進行動作分類預測每個人在畫面中的動作。
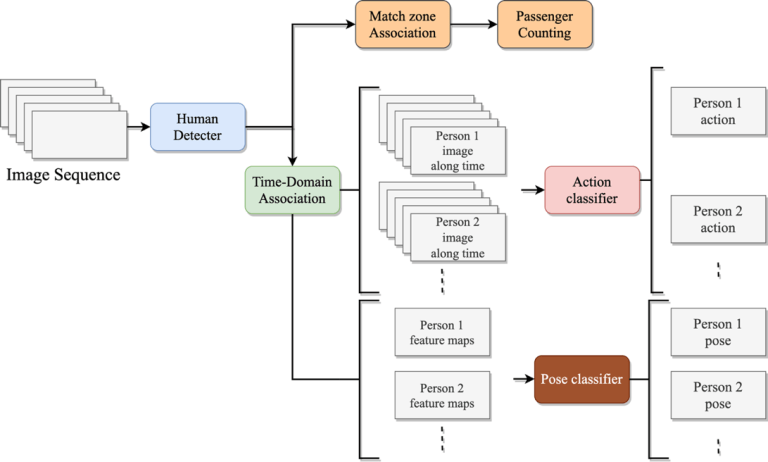
圖1 系統流程
最後本研究也對車廂中的人進行計數,了解車廂內的人數。由於拍攝畫面不足以涵蓋整個車廂,我們使用兩架相機進行車廂中的拍攝,然而會造成在利用偵測器的偵測結果進行計數時產生雙重計數的狀況。透過觀察畫面中乘客的位置,我們認為乘客的位置在兩架相機中存在規律,因此透過這些規律對乘客進行關聯。
1.資料蒐集
由於本研究受限於空間因素,相機拍攝為俯拍視角,相機的架設位置相較於其他研究較為不同。因此在本研究中我們透過自行在嘉義客運和科專計劃平台車蒐集的資料及公開資料集BOSS Dataset [3]進行人的偵測及動作分類。蒐集的資料人數上共23人,其中7人作為測試資料,16人作為訓練資料。
2.實驗結果
偵測上我們首先嘗試使用在COCO資料集上訓練的權重在我們的測試資料 上進行測試,其權重在COCO測試集上的mAP為60.9%,而在本研究的測試資料上的結果AP為53%。這個表現並不佳,乘客位置在相機上方的附近時,基本上偵測器並不能偵測到這些人,但是在離相機越遠的人上,由於拍攝視角的關係乘客外觀跟COCO資料集的資料差異越小,因此偵測結果不差。透過這個結果我們可以期待加上其它資料集訓練我們的偵測器會帶來一定的效果。單純在科專計劃平台車上訓練的結果AP為98.3%,另外加上BOSS、COCO資料集,增加訓練資料後的AP為98.5%,顯示加上其他大型數據集訓練可以提高偵測器的整體表現。偵測結果如圖2。

圖2 乘客偵測結果