工業技術研究院 資訊與通訊研究所 陳昭宏、陳柏瑋、黃健智、白炳川、徐銘駿、葉家毅、蔡孟哲、余俊德、許文彬、蔡文嘉
研究DNN模型壓縮方法和加速技術,成為目前學界、業界積極投入的目標。
前言
為使邊緣運算產品能夠導入AI應用進行智能化發展,同時克服運算效能瓶頸與功率消耗問題以提升使用者體驗,研究DNN模型壓縮方法和加速技術成為目前學界、業界積極投入的目標,其終極目的在於:讓壓縮後的DNN模型使用更少的權重數量,並以加快推論速度同時保持其預測準確性。其中DNN模型量化為該領域極為重要的一項技術,其概念是改變DNN模型的激活值(activation value)和權重值(weight value)可表示範圍,將原始浮點數運算轉成整數型態的運算,藉此來達到模型壓縮、推論加速的效果。然而模型量化過程對於實際硬體架構彼此間密不可分,必須確保軟體端的計算方法與使用位元數與硬體一致,才不會導致軟、硬之間量測出來的模型預測準確度有所差異,但AI硬體加速器普遍存在著少量多樣的現象,因此需有可針對硬體規格進行DNN模型量化的軟體端支援,才可快速因應多樣化的硬體架構進行模型最佳化。
精彩內容
- 量化感知訓練技術概念
- 權重值與激活值之偽量化處理
- 適應硬體架構之量化方式
量化感知訓練技術概念
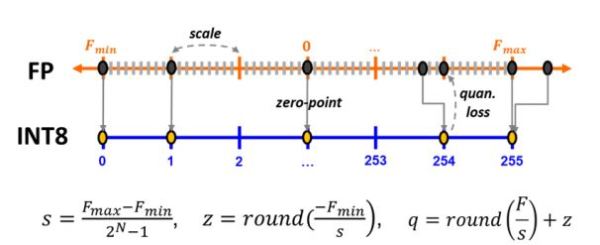
模型量化技術依其運用時機點,主要分成訓練後量化(post training quantization, PTQ)與量化感知訓練(quantization-aware training, QAT)2種方式,前者是基於已訓練完成的高準確度模型直接進行運算型態的轉換,中間處理過程不改變原始模型的權重值。而後者是由Google所提出[1],主要透過在模型的原始結構上插入偽量化運算(fake-quantization, FQ),藉以利用現有DNN訓練流程達到模型量化的功能。其概念如下所述:首先偽量化運算即是將浮點數轉成無號整數,然後再轉回浮點數的動作,而所需要的資訊分別為浮點數值域的最大(Fmax)、最小值(Fmin),以及預計要量化的位元數(N),該動作目的是要在浮點數值域的最大、最小範圍內劃分出2N位階,接著將所有浮點數值對應到最近的階上,因此數值雖依然為浮點數型態,但所有的值都只會落在位階上,最後依據此情況執行卷積層或全連接層運算,藉以模擬量化誤差並透過DNN重訓練來微調權重值以適應量化誤差。
整個量化過程首先需要計算出量化尺度(scale, s),其代表意義即是階跟階之間的間距值,當位元數較大時,將使得浮點數可表示範圍更精細,反之,可表示範圍則較粗糙;此外,Google的量化方式還引入零點對齊的動作,零點(zero point, z)即是浮點數值0對應到無號整數的值,其目的是要確保後續運算執行時,兩邊的輸入是在同一基準點上,使得0與0相加或與0相乘出來結果皆為0,同時也確保後續所有卷積層或全連接層只會是整數運算;在擁有上述資訊後,由浮點數轉成無號整數的量化值(quantized value, q)便可求得,其整體技術概念如圖1所示。
 E
E
圖1 量化感知運算原理
權重值與激活值之偽量化處理
權重值量化處理
顧名思義,權重值量化即是針對DNN模型中所有卷積層、全連接層的權重以及偏差(bias)進行量化轉換。當卷積層後面不存在批量標準化層(batch normalization, BN)時,只需在卷積層權重的輸出位置插入偽量化運算,該運算單元將自動記錄權重的最大/最小值,並將權重值先轉至無號整數,再轉回浮點數表示,雖依然為浮點數型態,但可表示範圍僅剩2N階,其轉換過程中所需要的量化尺度、零點資訊,皆可由先前的運算式求得;而針對偏差的處理上,該參數通常緊接於卷積層運算之後,在目前的量化感知訓練流程中並不做任何處理,直接使用原始浮點數做運算。實際轉成量化值將在後處理程序執行,其偏差的量化尺度資訊可透過卷積層的量化尺度與權重的量化尺度進行相乘求得,零點資訊則固定為0,其技術概念如圖2(a)所示。
激活值量化處理
激活值量化主要是針對DNN各層輸出進行的量化處理,但不需在每個運算單元後方都執行,通常可將卷積層+批量標準化層+激活函數看成一運算集合,只需在此運算集合後方加上偽量化運算即可,但因DNN模型架構的多樣性,要辨識出偽量化要在哪裡插入相比於權重值量化還要來的複雜,目前量化感知訓練主要針對底下3種普遍的DNN架構作考量,細節說明如下:
- 卷積層+批量標準化層+激活函數
如圖2(b)所示,現今受歡迎的DNN模型幾乎都存在此種運算集合,當判斷到此種架構時,偽量化運算將會被插在激活函數(例如:Relu 或 Relu6)運算之後。此外不同於權重值量化方式,DNN模型在訓練過程中,通常是採取小批量的方式來讀取訓練資料並輸入至DNN模型中,因此激活值的最大/最小值將以移動平均的方式來做紀錄,並執行有限範圍的浮點數轉換。
- 旁支層(shortcut layer)
如圖2(c)所示,在ResNets[2]證明旁支層可有效提升訓練效率以及模型精確度後,此種架構便陸續被採用,而因為執行相加運算時,兩邊輸入的量化尺度與零點資訊各不相同,因此需在輸出處插入偽量化運算來紀錄最大/最小值,並為下一層輸入提供統一的量化尺度,該資訊後續可協助硬體加速器在執行相加運算前,先將兩邊輸入值依據輸出的量化尺度先對準至同一基準點再執行相加,以確保執行結果正確。
- 合併層(concatenation layer, concat layer)
如圖2(d)所示,合併層主要用來將多個輸入進行合併,此架構主要存在於inception[3]與yolo[4,5]系列物件偵測模型中,算是目前經常被使用的運算單元。由於所有輸入的量化尺度與零點資訊各不相同,因此一樣需在輸出處插入偽量化運算來紀錄最大/最小值資訊並做量化處理,如此才可為下一層輸入提供統一的量化尺度。
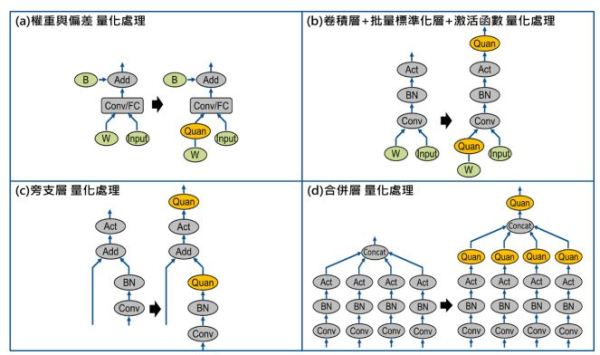
圖2 權重值與激活值於不同DNN結構之偽量化運算位置
適應硬體架構之量化方式
因應AI硬體加速器普遍存在著少量多樣的現象,為確保軟體端的量化計算方式和使用位元數與硬體一致,才不會導致軟硬體間量測出來的模型預測準確度有所差異。因此,這裡基於量化感知訓練流程,加入實際硬體架構運算考量來進行模型最佳化,目前所支援的硬體規格考量功能說明如下。
- 支援部份總和位元(partial-sum bit)調整
由於卷積運算是個不斷進行點乘與累加的程序,因此部份總和位元所支援的數量便直接影響軟硬體間的運算結果是否一致。通常在GPU硬體設計上與軟體端都是使用FP32表示,因此並不會有問題產生,但在嵌入式硬體設計上,為了效能、功耗、面積等考量,便會將其設計成INT32或甚至更小,因此在DNN模型量化過程就必須將此因素考慮進來。如圖3(a)所示,技術概念上便是在卷積層後的所有運算單元都插入裁切運算(clip operation, clip op),藉以限制卷積輸出的值域範圍,而此處的裁切極值可透過部份總和的最大、最小值(±2psum bit)乘上偏差的量化尺度來求得。
- 支援相加與合併運算的量化尺度同步功能
由於量化後的相加運算必須在執行前先將兩邊輸入統一到相同基準點,而該動作必需對整個特徵圖(Feature Map)做逐點處理,因此會花費許多運算時間;再者目前多數DNN模型於相加運算前都已存在偽量化運算,所以此連續兩次的偽量化處理理論上是可以被合併起來的。如圖3(b)所示,從數學理論上只要將兩邊輸入的最大/最小值同步,便可只用一次偽量化處理就直接進行相加運算。另外在合併運算處理上,先前是在輸出處統一做偽量化處理,但其實可直接針對所有輸入的最大/最小值進行同步,這樣一來合併運算出來的結果便直接是統一的量化尺度,如圖3(c)所示。
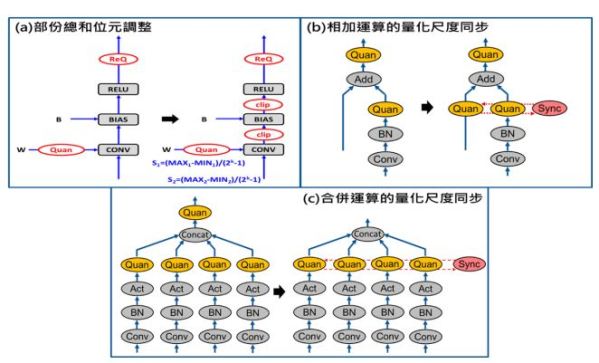
圖3 適應硬體架構運算之偽量化運算位置
實驗部分這裡選用4種圖像分類模型與2種物件偵測模型,並分別於ImageNet、VOC 2007資料集進行模型量化測試,同時評估其推論加速效果與預測準確度,綜合表1結果來看,上述6種DNN模型分別在GTX 1080/1080Ti(用於Yolo V2)的硬體上時,其INT8模型與FP32模型相比,平均可提升推論速度達1.7倍以上,且精確度損失不超過1.8%。此外與Nvidia TensorRT[6]模型量化相比,其精確度誤差也僅在±0.5%內,且同時擁有相同的推論加速效果,但不同於TensorRT僅支援於自家GPU硬體,這裡所發展的適應硬體量化技術可因應多樣化的AI硬體加速器架構進行模型最佳化。
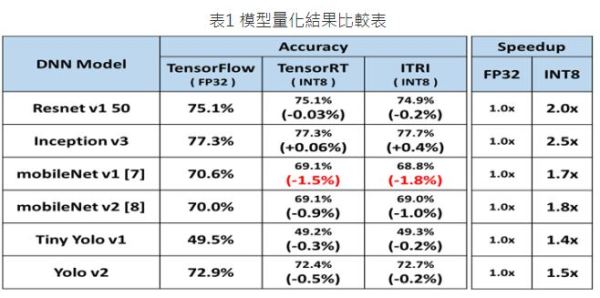
表1 模型量化結果比較表
結論
因應AI硬體加速模型壓縮的目的旨在減少DNN模型所需的運算量、權重數,藉以有效提升推論速度並維持原始預測準確度,而透過可適應硬體架構的量化感知訓練方法,藉由在原始DNN結構加入偽量化運算,並在模型重訓練過程考慮所有量化損失對精確度之影響,進而回去修正模型權重參數以回復準確度。後續可在結合其他壓縮研究如模型剪枝、知識蒸餾等技術,以達到在不損失預測準確度前提下,逐步產生運算速度更快的模型,同時也嘗試讓現有技術不斷測試於推陳出新的DNN模型架構上,藉以讓此技術成果能夠更加穩定與成熟。
參考資料
[1] Benoit Jacob, etc., “Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference”, arXiv:1712.5877 [cs.LG].
[2] He Kaiming, etc., “Deep Residual Learning for Image Recognition”, arXiv:1512.3385 [cs.CV].
[3] Christian Szegedy, etc., “Rethinking the Inception Architecture for Computer Vision”, arXiv:1512.0567 [cs.CV].
[4] Joseph Redmon, etc., “You Only Look Once: Unified, Real-Time Object Detection”, arXiv:1506.2640 [cs.CV].
[5] Joseph Redmon, etc., “YOLO9000: Better, Faster, Stronger”, arXiv:1612.8242 [cs.CV] .
[6] NVIDIA TensorRT. https://developer.nvidia.com/tensorrt
[7] Andrew G. Howard, etc., “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications”, arXiv:1704.4861 [cs.CV].
[8] Mark Sandler, etc., “MobileNetV2: Inverted Residuals and Linear Bottlenecks”, arXiv:1801.4381 [cs.CV]