
人工智慧的影像辨識能力甚至超過了人類,但只要我們在影像上加入一些微小的擾動,就可以讓這些影像辨識模型完全失效。
人工智慧被導入到生活中各領域應用,尤其影像辨識能力甚至超過了人類,但只要我們在影像上加入一些微小的擾動,就可以讓這些影像辨識模型完全失效。對抗性攻擊從影像延伸到現實,近年來,研究人員在深度學習上的攻防戰都顯示需要重視深度學習系統中的安全問題,以提高人類對人工智慧產品的信任度。
人工智慧的安全漏洞
在過去的十年中,人工智慧已在生活和商業的各個領域的實際應用中證明了其價值。隨著運算速度顯著提升、運算成本顯著降低以及日趨成熟的演算法,深度學習技術在語音、文字內容、影片等資料類型的處理中被頻繁地導入到各個產業應用中,從而創造出龐大的價值。
然而,深度神經網路已被證明容易受到對抗樣本的攻擊,對抗樣本是一種攻擊者透過精心設計的小雜訊所製作的惡意樣本,如圖1所示,對抗樣本會誤導深度神經網路做出錯誤的決定,對深度學習模型的安全性產生了嚴重威脅,例如:對自駕車需要識別和分類的道路交通標誌進行對抗攻擊,讓自駕車系統將停車標誌判讀為「繼續行駛」或其他標誌,可能導致汽車誤判,從而導致嚴重後果。而在探討對抗樣本的成因時,Szegedy 等學者[3]發現對抗樣本具有可遷移性(Transferability),即針對一種深度學習模型生成的對抗樣本,也可以成功誤導其他模型的預測判斷,因此攻擊者可以在不存取底層黑盒模型的情況下欺騙人工智慧系統。對抗樣本不僅僅是存在於實驗室的研究展示,對抗樣本已經可以在實體生活中實現並影響最快、最準的AI偵測技術。.
![圖1 分類任務中遇到對抗樣本的示意說明[1],即使「香蕉」輪廓很明顯,分類器仍將影像錯誤地辨識成「烤麵包機」](https://college.itri.org.tw/ashx/GetNASImagebyAttNo.ashx?attNo=ce9ab78f-26fa-46b7-b363-8b1d90c13917)
生成對抗雜訊的方法,不是隨機生成的雜訊,而是依據深度學習模型和輸入樣本的梯度(Gradient)生成對抗雜訊,在模型訓練裡,梯度對應的是模型參數該如何調整更新,模型參數隨著梯度不斷的更新,模型的分類準確度也就愈來愈高。反之,在進行對抗攻擊時,我們觀察輸入樣本取得的梯度,對每個樣本數值的梯度方向進行微小的修改後,使模型的預測結果可以透過非常細微的變化而發生很大的變化。
![圖2 輸入樣本「熊貓」,並取得梯度,對每個樣本數值的梯度方向進行微小的修改後,使樣本被AI模型錯誤分類成「長臂猿」[2]](https://college.itri.org.tw/ashx/GetNASImagebyAttNo.ashx?attNo=72794025-38a0-4f38-a1d8-45c660863c72)
圖3是數位化對抗攻擊(Digital Attacks)在數位化資料上對抗樣本的呈現,被攻擊的目標是數位化資料,如影像、語音、影片、文字內容等,數位化攻擊是透過直接修改輸入樣本的數值來製造對抗樣本,進而誤導人工智慧的判別預測,數位化攻擊在人類無法察覺的異常影像結果中隱藏了攻擊的擾動信息。數位化攻擊為攻擊者提供了更多攻擊方法的選擇,並降低了成功攻擊的難度,因為攻擊者不需要考慮現實生活中物體的形態會使對抗攻擊製造的數值擾動有失真的可能性。
![圖3 數位化對抗攻擊(Digital Attacks)在數位化資料上對抗樣本的呈現[2][3][4]](https://college.itri.org.tw/ashx/GetNASImagebyAttNo.ashx?attNo=36debf88-0c3f-4a74-ba62-d3a659e3a2a1)
與數位化對抗性攻擊相比,在現實生活中實施對抗性攻擊對於攻擊者來說是一項更具挑戰性的任務,因為現實生活中的被攻擊對象會先被相機或感測器數位化轉換,才會輸入到AI模型中,這個轉換過程會破壞精細對抗擾動的細節,在複雜的現實環境中,還含有亮度或是遮擋等環境因素,降低攻擊者攻擊的有效性。然而,近年來有大量關於實體化對抗攻擊相關研究顯示,實體化對抗攻擊會更進一步損害深度學習技術在現實生活中的實用性和可靠性。
圖4流程為實體化對抗攻擊(physical attacks)的流程概述,攻擊者一開始先準備對抗性擾動,例如,使用彩色印表機列印對抗式干擾,並放置於在攻擊目標上, 第二步即進行實體化對抗攻擊驗證,部署感測器設備,例如RGB 鏡頭,並調整鏡頭依據多樣化情境進行現實生活中實現對抗攻擊干擾AI識別系統驗證,例如,鏡頭移動時攻擊目標是固定的,當鏡頭固定時攻擊目標會移動(道路監控),以及攻擊目標和鏡頭同時移動(自駕車行駛時)。圖5是對抗擾動影像在現實生活上的呈現,對抗擾動影像在列印之前在數字值域中進行了優化,製作對抗性干擾置入在現實生活的物體上來欺騙檢測系統。
![圖4 實體對抗樣本的製作過程概述[5] 圖5 實體化對抗攻擊在現實生活中的案例呈現,多角度下YOLO目標檢測器都無法偵測穿著有對抗擾動衣服的人[8][16]](https://college.itri.org.tw/ashx/GetNASImagebyAttNo.ashx?attNo=bbb53d4a-5784-4509-8b05-869224ba256e)
AI弱點測試與改善現況與實例
透過生成多種對抗樣本,輸入深度學習模型進行測試,進行AI弱點測試,評估AI模型在面對對抗樣本時的模型推理和分類功能的準確性。開源軟體有IBM研究團隊的Adversarial Robustness Toolbox[15],開發人員可以此工具生成對抗樣本檢測模型的穩固性,透過多樣化的對抗樣本記錄模型對不同干擾的輸出結果。而防禦的研究緊跟在攻擊的研究之後,現今常見的抵禦方式有:(1)對抗訓練(adversarial training)[9][10],透過在訓練集中加入多樣化的對抗樣本,在模型訓練時即強化模型抵抗擾動輸入;(2)透過輸入預處理和轉換等方式[11][12],如圖6所示,限制輸入以過濾擾動;(3)透過對抗樣本和正常一般樣本的差異特性,建立偵測模組過濾異常輸入[13]。
![圖6 輸入樣本基於隨機預處理轉換的流程[12],限制輸入以過濾擾動](https://college.itri.org.tw/ashx/GetNASImagebyAttNo.ashx?attNo=10932bfa-79c6-45ec-abd9-76645d3c9223)
此外,美國國家標準暨技術研究院(National Institute of Standards and Technology,NIST)提供AI安全測試平台—Dioptra,讓一般工程師可以透過Dioptra平台評估AI模型的脆弱性,Dioptra平台提供常見的對抗樣本生成演算法,如:DeepFool[18]、Fast Gradient Method[2]、C&W attack[17]等,透過對抗樣本的輸入檢測幫助研究人員加強AI模型對潛在風險的防禦,讓AI系統變得更加安全。 Dioptra AI安全測試平台,同時也提供讓AI模型強化的相關功能,包括使用對抗訓練、輸入樣本進行模型推論前的樣本預處理以過濾擾動等。Dioptra AI安全測試平台,以簡單的OpenAPI呼叫方式,建立AI模型的評估流程,快速完成AI模型的安全評估工作。
![圖7 Dioptra安全測試平台架構,平台建立在微服務(microservices)架構之上,可部署在伺服器叢集或個人筆電上[7]](https://college.itri.org.tw/ashx/GetNASImagebyAttNo.ashx?attNo=9c52a824-d66a-4b91-9729-e5717f184adf)
未來發展方向與相關議題
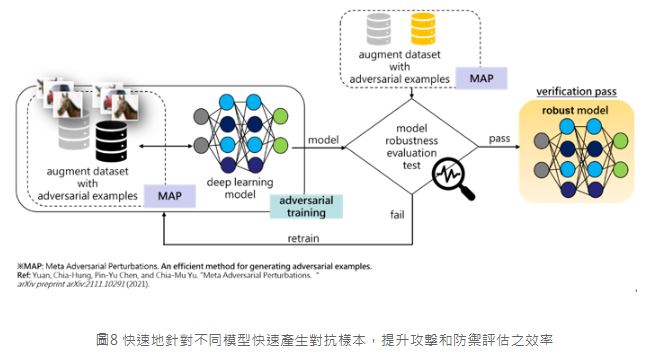
工研院和陽明交通大學目前正著手研究深度學習系統之信任度與風險分析,因為需要大量的對抗樣本進行AI的強健度評估,同時大量的對抗樣本可用於對抗訓練,而大量的對抗樣本除了多樣化還需要時間成本,因此近期提出利用元學習(meta learning)的概念來生成對抗樣本[19]使之可以快速地針對不同模型產生對抗樣本,如此將可讓對抗性攻擊和防禦的速度加快數倍。未來相關技術工研院將應用於AI安全檢測以及協助產業強化AI安全與韌性兩大主軸上,期待可以協助政府相關部門更好地確認所導入的AI應用,其核心模型的安全性保障是否足夠,同時因應未來歐盟在可信任AI、ISO組織以及如美國NIST等規範標準上之要求,幫助產業的AI應用輸出,在安全規範上可以接軌國際︒
結語
或許在我們肉眼看來,輕微的影像擾動不會造成誤判,但對於AI模型來說,情況並非如此。自人工智慧發展以來,對抗攻擊研究涵蓋了許多領域的對抗性攻擊和防禦,希望透過這些努力,提醒研究人員在使用人工智慧技術框架時,需要將深度學習系統中的安全問題列入考量,以提高人類對終端產品的信任。