創鑫智慧 營運長 陳建良

由AI、Big Data、Cloud Computing、DSA與Energy Efficiency建構的產業逐漸落實,ABCDE發展的大趨勢隱然成形。
AI技術快速發展,模型快速疊代更新,算力需求每3.5個月即翻倍成長[1],位處台灣的AI新創公司,如何深耕核心技術並把握市場機會,實為一重要課題。本文試從筆者所觀察到的ABCDE趨勢為基礎,闡述研究團隊與公司如何在這個大架構下,找到產品的定位並發揮優勢,藉由參與公開的國際評比錨定技術與產品價值,以質變突破量變的方式,將開發的方案逐步導入市場。
趨勢
人工智慧(AI),大數據(Big Data)與雲端運算(Cloud Computing)的匯聚,創造我們目前的智慧生活。尤其是網路、電商與社群媒體的發展讓人人願意上網並留下數位足跡,業者活化這些資料並加以訓練,萃取出有用的資訊形成個人化的推論模型,也讓生活更智慧。
隨著資料持續累積,龐大的數位資料造成運算上與能耗上的負擔,運算效能與功耗的問題開始被討論,以CPU與GPU為主的雲端運算是否就是最好的運算架構呢?關於這個問題,JOHN L. HENNESSY與DAVID A. PATTERSON兩位大師在New Golden Age for Computer Architecture給了一個參考答案:Domain Specific Architecture (DSA)並以TPU (Tensor Processing Unit) 做實現,也激起雲端業者自行開發晶片與許多新創業者投入專用晶片的開發,以更優異的效能 (Performance)與能效(Energy Efficiency)方案,希望分食Cloud AI Training/Inference Accelerator的大餅。
致力於推進機器學習及AI的開放工程聯盟MLCommons也從2021年起,在測試項目中除效能指標外開始加註power metric[8],引導廠商注意晶片功耗的問題。因此我們認為AI晶片與產品未來應會以Inference/Joule為性能指標,而不再只是單純的使用TOPS/Watt (No. of MAC x Max. Freq. /Watt)這個效能參數。因為,考量晶片的架構與模型的匹配性、資源的使用率及運算結果的Inference/Joule,對使用者而言才是真正有意義的指標。
由AI、Big Data、Cloud Computing、DSA與Energy Efficiency建構的產業大未來逐漸在產業落實,ABCDE發展的大趨勢隱然成形,如圖1所示。
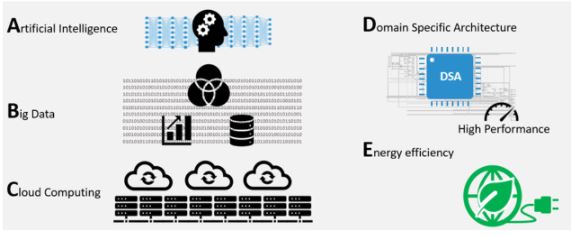
圖 1 ABCDE趨勢(資料來源:創鑫智慧)
創新
在ABCDE的發展環節中,如何找到切入點,建構技術與產品技術優勢呢?我們以清大林永隆教授實驗室發展的HarDNet為例,說明如何藉由AI模型的創新與功耗優化,做AbcdE式的模型創新,在現有的晶片架構下發揮最大效益。另外,我們以創鑫智慧所發展的RecAccel系統說明如何把握模型與架構之間不匹配造成的價值缺口,以abcDE式的架構創新,解決客戶的痛點。
模型創新:HarDNet
HarDNet,如圖2所示,是由清大林永隆教授研究團隊所發展的CNN骨幹網路之一,藉由減少DenseNet架構中layer之間的連結,降低資料搬運次數,減緩資料吞吐的頻寬壓力,增進整體的運算速度。為了強化layer之間因連結減少造成擷取的特徵值變少,模型準確率下降的問題,研究團隊依晶片的運算特性與On-Chip Memory (Cache)大小,重新設計每一layer的權重數與layer間的連結方式,用增加運算量的方式擷取更多的特徵值,藉此維持模型準確率。簡言之,HarDNet模型特性是可針對不同的晶片架構與On-Chip Memory的大小調整layer數多寡與權重數,優化運算與記憶體頻寬,達到最佳準確率與效能。同時,由於資料進出記憶體是最耗能的動作,降低記憶體進出也達到降低功耗,增進Energy Efficiency。HarDNet的節能優勢在美國史丹佛大學、臉書、加拿大Mila、McGill大學聯合發表的一篇論文得到認可,在多種CNN網路耗電量評測中,HarDNet39ds取得低耗電量的好成績[3],如圖3所示。。
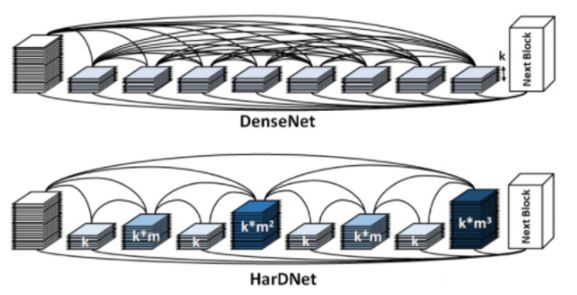
圖 2 HarDNet (資料來源:Low-memory Traffic HarDNet[2])
HarDNet的優異效能在電腦視覺領域獲得許多驗證,在2020年全球低運算電腦視覺競賽(Low-Power Computer Vision Challenge, LPCV)中,搭載在FPGA (Ultra96-V2)與指定的手機平台(LG G8)上驗證模型表現,分別獲得第二名與第三名的佳績[10]。
除物件偵測、分類、辨識外,在醫療影像方面,HarDNet的表現也可圈可點,精準度與效能皆已達實用階段。
HarDNet-MSEG:
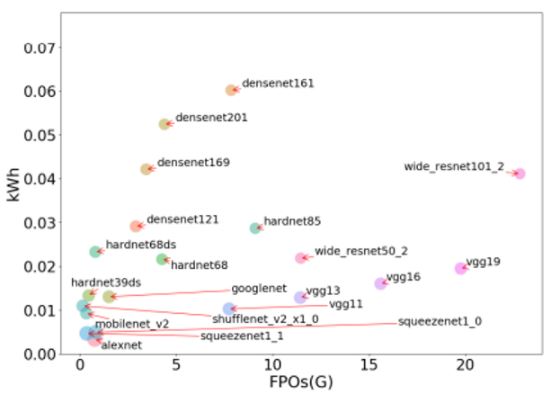
圖 3 各模型之碳足跡比較(資料來源:[3])
結直腸癌(CRC)的發病率已位居世界第三很多年了。因此,如何預防CRC是一個重要的全球性問題。早期發現大腸腺瘤性息肉並切除可大大減少CRC的發生率。目前息肉的檢測是由內視鏡醫師手動進行,很大程度上取決於醫生的經驗和能力,因此有必要發展兼具高準確率與高效能的息肉辨識與分割系統,輔助醫師診斷。
HarDNet-MSEG是基於HarDNet68骨幹網路和一個簡單的編碼器-解碼器架構,如圖4所示,在CVC-ColonDB、EndoScene、ETISLarib、Polyp DB、CVCClinic DB 和Kvasir-SEG等資料集的評比中,經第三方的評比,如表1所示,展現極高的精準度與推論效能。
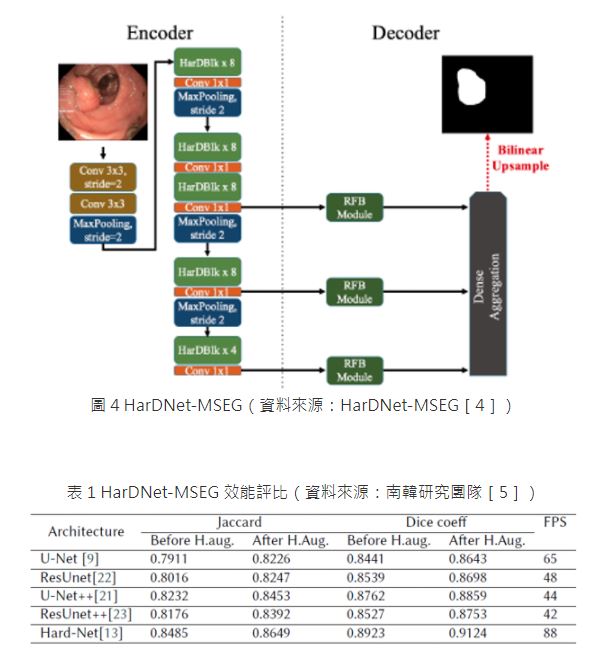
HarDNet-BTS:
在腦部腫瘤的治療方式當中,通常有手術切除、放射治療、全身性藥物治療,而在診斷要使用哪種治療方式時,需要能夠準確看出腫瘤的位置、範圍以及體積,但是想要完成以上條件並不是那麼的容易,若是可以透過AI提供腫瘤的位置以及範圍,如圖5所示,輔助醫師做判讀,將可發揮極大的效益。
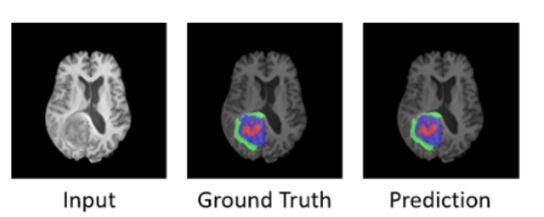
圖 5 AI提供腫瘤的位置以及範圍(資料來源:BraTS 2021)
HarDNet-BTS是基於HarDNet的3D模型,參加2021年MICCAI(Medical Image Computing and Computer Assisted Intervention Society)所舉辦的Brain Tumor Segmentation Challenge(BraTS),在960個參賽團隊中脫穎而出,首次參賽就在驗證階段取得前9名的好成績(依字母排序)[6],如圖6所示,並受邀發表報告。

圖 6 BraTS 2021驗證階段入圍團隊(資料來源:BraTS 2021)。
架構創新:RecAccel
推薦系統(Recommender System)是一種資訊過濾系統,可用於預測用戶對物品的「評分」或「偏好」,大量應用於各行各業,推薦的對象包括電影、音樂、新聞、書籍、學術論文、搜索查詢等。依據MAXIMIZE Market Research的報告,如圖7所示,全球的推薦系統引擎(Global Recommendation Engine Market)的市場,預估將有大幅度的成長,市場規模從2019年的12億美元成長至2027年的85億美元,是一塊值得耕耘的市場。
隨著數位化轉型,有愈來愈多的資料與使用情境,推薦系統也面臨幾項挑戰:資料量及運算量大,且逐年增加中;運算需即時,30毫秒以內需完成1次推論(Latency bound);CPU/GPU運算耗電量高(Energy bound);模型大小與模型準確度限制等,急需有適當的模型、架構與加速方案,解決上述問題,如圖8所示。
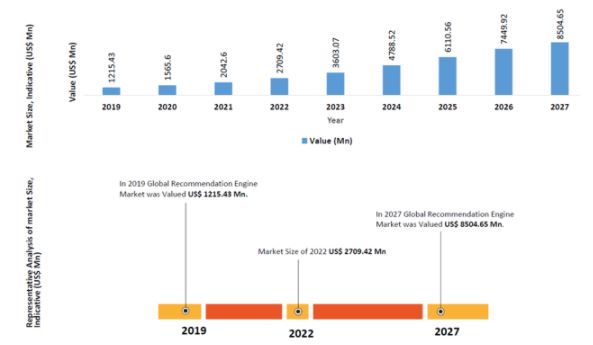
圖 7 Global Recommendation Engine Market Overview (資料來源:MAXIMIZE Market Research,2020)
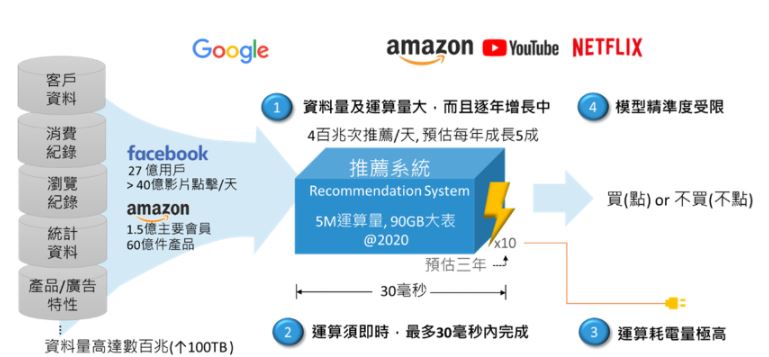
圖8 深度學習推薦系統及其特性(資料來源:創鑫智慧整理2021)。
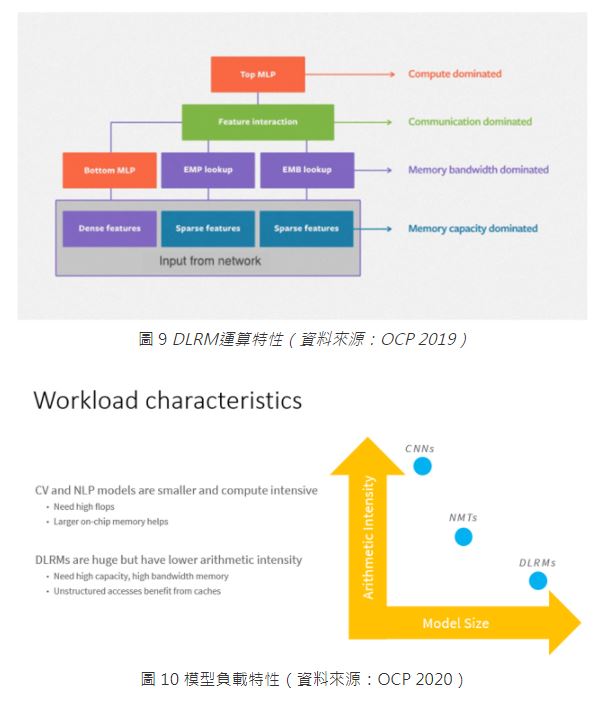
有別於Content-based Filtering與Collaborative Filtering模型架構,Google於2016年引入深度學習的方式發展推薦系統,以end-to-end的方式建構Wide-and-Deep推薦模型。2019年Facebook更將其使用的深度學習推薦系統模型(DLRM,Deep Learning Recommendation Model)[7]開源,並在OCP大會上剖析其Memory-bound的模型特性與Embedding Table & Lookup負載特性與遭遇到的挑戰,如圖9與圖10所示,之後更將DLRM推入MLCommons(MLPerf)組織,成為Data Center類別重要的測試項目,顯見其重要性。
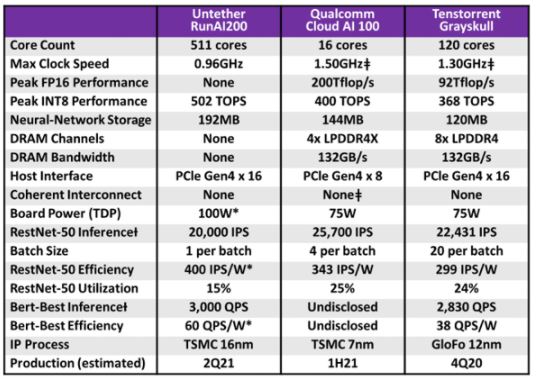
然而,目前的Cloud AI Inference Accelerator幾乎都是以解決Computing-bound為核心架構,並未考慮到Memory-bound運算模型的需求,造成價值缺口。此外,其架構與運算資源的使用率仍顯偏低,如表2所示,能效上的表現並不理想。
表 2 推論專用晶片比較(資料來源:Microprocessor Report 2020[11])
RecAccel-FPGA系統,如圖11所示,重新架構推薦系統適用的DSA、記憶體系統與存取機制、打造推薦系統模型壓縮技術與Software Stack等,提升資源使用效率(MAC UT rate達80%以上),大幅提升執行AI推薦系統推論時的效能與能效,同時解決客戶面臨的Memory-bound、Latency-bound與Energy-bound的痛點。 該系統目前已成功完成DLRM系統建置做為POC,並連續參加MLPerf v0.7 、MLPerf v1.0 與MLPerf v1.1推論運算效能評測[7],是唯一一家新創公司,也是唯一的DSA解決方案。
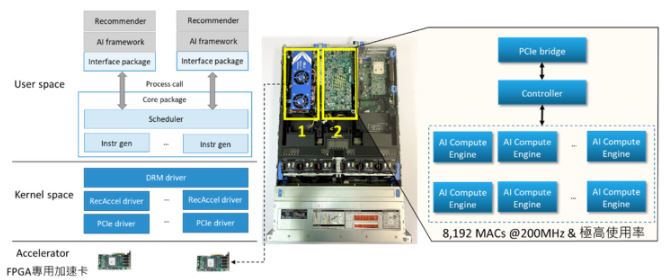
圖 11 RecAccel-FPGA系統(資料來源:創鑫智慧2021)
創業
根據研究,當產業結構發生重大變革,技術、客戶、市場、政策……等的不連續性造成重大的產業價值缺口時,適合創業家利用時勢創業或具創業家精神的管理團隊開創新事業;當產業相對處於成熟期時,產業上、下游或鄰近產業的價值變遷會造成價值移轉,管理團隊則應密切追蹤產業趨勢,形朔轉型的契機,持續創造價值[9]。
AI被稱作第四次工業革命的核心,具有不連續性的發展特性,對未來生活形式和產業發展的影響既深且廣,正適合創業家投入形塑未來。 創鑫智慧為科技部半導體射月計畫支持之「智慧終端系統晶片研發與新創事業計畫」所技術轉移促成之新創公司,定位在「AI Compute Acceleration Solution Provider」,以優異的學術研究為基底,結合具實務經驗的研發團隊與本土資金,緊扣ABCDE的大趨勢,發展技術、架構與方案,區隔市場並滿足該市場的需求。
HarDNet在醫療影像上的應用已獲得醫師團體的青睞,RecAccel完成POC後也募得開發ASIC的資金,希望創鑫智慧能在Cloud AI Inference Accelerator全球競局中拿下關鍵的一席。
結論
本文從Outside-In的ABCDE的觀點,重新檢視HarDNet與RecAccel的創新方程式,提供給讀者參考。創業家或廠商可依據自身在AI建模、領域資料、運算服務、加速架構或能耗控制等方面的核心能力,在ABCDE的相關環節中定位自己的發展利基,或是結合策略夥伴,構築競爭優勢。 台灣擁有全球最完整的半導體供應鏈、伺服器產業與資通訊體系,且有相當多的臨床醫學數據,值此AI產業革命浪潮發端之際,理應發揮核心能力與在地產業優勢,乘風破浪,開創新局。 帆已揚,東風起,君更何待!
參考文獻
[1] AI and Compute: https://openai.com/blog/ai-and-compute/
[2] HarDNet報導: https://www.ithome.com.tw/news/141194
[3] Peter Henderson, et al., Towards the Systematic Reporting of the Energy and Carbon Footprints of Machine Learning
[4] Chien-Hsiang Huang, et al., HarDNet-MSEG: A Simple Encoder-Decoder Polyp Segmentation Neural Network that Achieves over 0.9 Mean Dice and 86 FPS
[5] Raman Ghimire, et al., An Augmentation Strategy with Lightweight Network for Polyp Segmentation
[6] BraTS Challenge 2021: Conference
[7] DLRM: https://ai.facebook.com/blog/dlrm-an-advanced-open-source-deep- learning-recommendation-model/
[8] MLCommon Inference Results: https://mlcommons.org/en/news/mlperf-inference-v11/
[9] 陳建良,2013,開放式創新模式及演化之研究 - 以GUC為例,國立台灣大學碩士在職專班商學組碩士論文。 [10] LPCV: https://lpcv.ai/competitions/2020
[11] MICROPROCESSOR Report: https://www.linleygroup.com/mpr/article.php?id=12385