工業技術研究院 資訊與通訊研究所 董明智
國立清華大學 劉靖家教授

TVM提出了一個端到端的深度學習編譯軟體架構,以解決跨多種硬體後端的深度學習編譯優化問題。
前言
AI應用幾乎都是以各種Tensorflow、Pytorch、MxNet、Keras、Caffe等深度學習框架(Framework)進行開發,最後要轉移框架所開發的神經網路模型(Neural Network Model)部署到AI晶片上執行,早期只能依靠人力設計程式介面,並使用半自動方法產生控制程式,但當設計的神經計算網路趨向多元化複雜化後,我們必須有編譯軟體支援,將框架中的深度學習運算透過編譯軟體堆疊(Software Stack)進行各種計算轉換與優化程序,產生可以在AI晶片上執行的指令集與程式碼。深度學習框架雖也可以將模型編譯到CPU或GPU上執行,這仰賴於硬體廠商提供深度學習函式庫,讓框架所支援的運算進行編譯介接,但許多模型推論(Inference)時的優化並沒有被考慮或實作。
目前深度學習框架只能支援少數的CPU/GPU設備,這種支援依賴於特定的CPU/GPU深度學習函式庫,當愈來愈多樣的AI晶片出現時,硬體設備廠商在整合多樣性的晶片推出產品時,對於深度學習框架的支援便會變得相對困難,因為不同晶片的記憶體結構、計算能力、計算特性都有很大的差異,如何設計一套深度學習編譯軟體堆疊可以將AI應用編譯到各種不同的硬體後端執行,讓神經網路模型在異質硬體設備上的執行具有可攜性,也就是透過目標硬體設定可以將一個模型依據需求編譯到指定的硬體上執行而不用重新開發模型,而且要能依據硬體特性進行編譯優化,這是AI晶片能否成功推向市場的挑戰。
精彩內容
- 傳統深度學習框架的編譯推論方式
- TVM深度學習軟體堆疊
- TVM深度學習編譯器的展望
傳統深度學習框架的編譯推論方式
目前常見的深度學習開發框架,都會提供深度學習的API套件,讓AI工程師可以快速開發神經網路模型,而框架的編譯流程如圖1所示,將模型轉化成高階的數據流程圖(亦稱為計算圖,Computational Graph Intermediate Representation),圖中的每個節點代表一個計算單元(如:conv2d、pooling、gemm等),為了將高階的深度學習運算(Operation)映射到硬體上執行,必須依賴硬體支援的低階深度學習函式庫(例如:NVidia GPU/CuDNN、AMD GPU/ROCm),每個計算單元必須映射到對應的函式(如圖1所示)再轉成底層可執行於硬體的程式碼。這種編譯方法的限制在於: (1)如果計算單元沒有支援的函式進行對應,則無法進行運算;(2)硬體廠商必須針對硬體特性提供底層的深度學習函式庫;(3)必須在Tensorflow與Pytorch等前端框架增加支援硬體函式庫的程式碼;(4)深度學習快速發展,如果有新的運算產生,則必須新增底層函式支援與之對應;(5)如果要針對計算圖進一步分析運算特性並進行優化,讓計算效能提升,例如:自動微分、動態記憶體管理[1][2][3]、或進行運算融合(Operator-Fusion),經過優化後所產生的新運算,如果函式庫中沒有對應的支援函式則無法在硬體上執行。
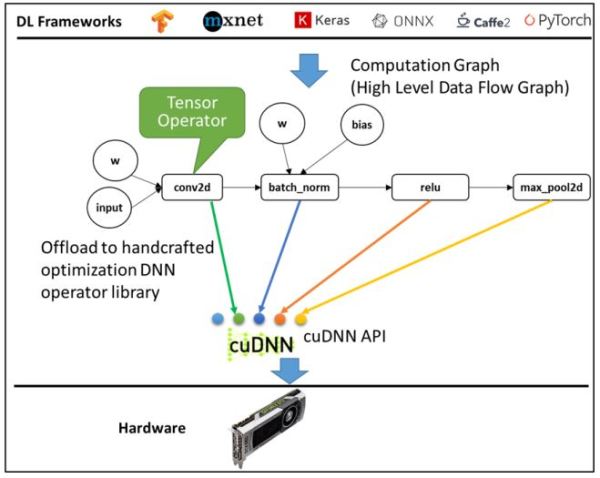
圖1 深度學習框架的編譯流程(NVidia GPU為例)[5]
深度學習框架編譯後的執行效能取決於支援硬體執行的函式庫,硬體廠商必須花費許多工程師人力開發深度學習函式庫,而且必須讓函式庫連結到各框架中,才能讓框架編譯支援硬體。然而,此種編譯方法對於正在蓬勃發展中的AI晶片廠商造成實際的難題,實務上許多大型廠商自行開發深度學習編譯軟體來支援多晶片執行環境,例如: Intel的OpenVINO、ARM的ARM NN、Qualcomm的SNPE(Snapdragon Neural Processing Engine)等,但在開發過程當中,針對不同應用環境(如Android或Bare-metal沒有作業系統等),或不同加速器類型(如DSP 或硬體加速器等),都需要修改或新增支援的編譯工具,產生出非常複雜的流程。同時,各種開源AI編譯器也蓬勃發展如Facebook的Glow[6]、Intel的nGraph[7]、華盛頓大學與Amazon主導的Apache TVM[4]等,這些深度學習編譯器可以支援現有框架開發的神經網路模型,將模型透過軟體編譯到單個晶片或多晶片後端執行,主要目的在於提供各種優化的彈性應用範圍,而不需要針對在每一種不同環境或硬體架構,進行全面改寫工具,下個章節將以Apache TVM為主,進行深度學習編譯技術介紹。
TVM深度學習軟體堆疊
TVM設計了從前端框架到後端硬體的端到端(End-to-End)編譯軟體架構,為了支援各種硬體後端的計算圖優化(Computational Graph Optimization)和張量計算優化(Tensor Level Optimization),從深度學習框架模型導入高階數據流程圖,轉化成TVM本身的計算圖表示方式(Relay IR),再進行各種編譯優化程序,並產生適合硬體後端計算特性的優化後低階程式碼,TVM不僅能支援CPU、GPU的深度學習編譯,更能支援FPGA、AI晶片等的編譯流程,在編譯優化技術上需要面臨幾項技術挑戰: (1)不同晶片有不同記憶體架構(例如:L1 Cache、L2 Cache、Main Memory、Shared Memory、Global Buffer等各式記憶體);(2)編譯優化架構如何支援各種不同硬體的編譯程序;(3)如何對應不同硬體的函式庫進行編譯優化;(4)如何支援各種不同前端框架所開發的神經網路模型之編譯流程。
TVM提出以下方法來因應上述技術挑戰: (1)引入Graph Rewriter(如圖2中的Framework Parser),並提出了Relay IR的深度學習運算表示方式,讓TVM可以支援各種不同的深度學習框架所開發的神經網路模型,TVM Frontend Parser包含了Relay IR格式的深度學習運算定義,可以將各種模型格式轉譯成Relay IR統一的表示方式,再從Relay IR開始進行各種編譯優化,目前TVM Frontend Parser可支援的輸入包括了Caffe2、CoreML、Keras、ONNX、Pytorch、Tensorflow、TFLite等[10],幾乎包括了各種目前主流框架的格式;(2)引入Halide[8]機制將演算法(Compute)與排程(Schedule)分開定義,提出Tensor Expression Language讓編譯器開發人員可以定義各項深度學習張量運算的演算法與排程,例如我們可以定義conv2d (二維卷積)主要演算法的迴圈,再依據硬體特性定義conv2d_nchw(n代表batch、c代表channel、h代表height、w代表width)、conv2d_int8、conv2d_hwcn 等不同排程,這些不同迴圈的實現方式,可以靈活地針對不同硬體需求進行排程優化;(3)提出自動化排程優化機制(Automated Schedule Optimization Framework),將排程優化以深度學習方法探索最佳的排程方案,簡化工程師根據硬體特性進行排程優化程式撰寫的程序。
TVM編譯軟體堆疊
TVM深度學習編譯軟體堆疊如圖2的架構說明,為了能支援不同格式的深度學習開發框架,透過轉換模組(Parser)將深度學習框架的運算轉譯成TVM的計算圖表示方式(Relay IR);再進行計算圖優化(Graph Optimization),包含:運算融合(Operator Fusion)、資料布局轉換(Data Layout Transformation)、常數運算簡化(Constant-Folding)、運算轉化(Simplify Inference);接著依據晶片特性開發優化編譯技術,進行張量計算優化(Tensor Level Optimization),包含:迴圈轉換(Loop Transformation)、跨執行緒記憶體複用(Thread Binding、Thread Cooperation、Cache Locality)、張量化(Tensorization);最後開發支援運算執行的Runtime模組,將AI晶片支援的運算導引至CPU及AI晶片執行。TVM在張量計算優化的演算法中導入自動排程調優化(Automatic Schedule Optimization)功能,透過機器學習方式進一步調校優化張量計算的排程,提升運算效率。
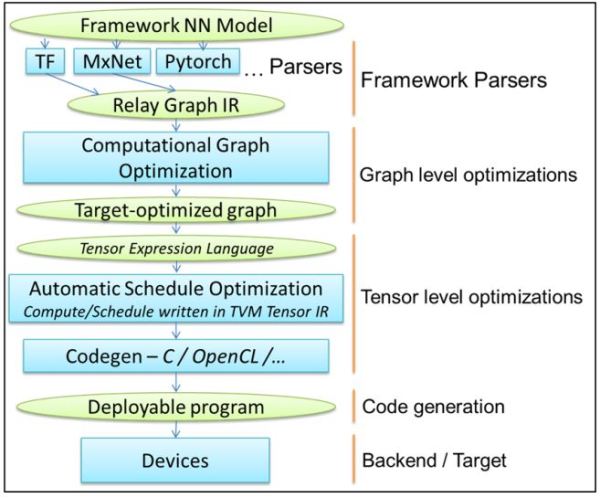
圖2 TVM深度學習軟體堆疊
計算圖優化
計算圖用於表示一個深度學習神經網路的高階數據流程圖(如圖1所示),計算圖優化會分析圖中所有計算單元的運算任務,依據數學計算特性及各運算任務之間的記憶體使用關聯性,進行運算任務之間運算融合、數學整合或拆解簡化、無用程式碼移除、以及Data Layout轉換等優化程序。目前TVM以自定義的Relay Graph IR函式用於表示神經網路模型的計算圖,主要是為了解決傳統編譯器中難以表達神經網路模型中的各種複雜運算子。以下就幾項常用的計算圖優化方法稍作陳述: (1)數學運算分析與簡化(Algebraic simplification):透過數學運算順序調整、數學算式拆解等方式轉化成較簡單的數學算式,以及常數折疊 (Constant folding)處理;(2)運算融合:根據運算特性進行多個運算的融合,藉以降低運算過程中將資料回存主記憶體的存取次數,藉以提升效能;(3)Dead code elimination:分析運算程式,將沒用到的程式碼移除;(4)資料佈局轉換: 找出後端晶片執行運算時的最佳Data Layout,在計算圖IR中針對需要進行Data Layout轉換的運算插入轉換Tensor,當編譯器完成編譯後於晶片後端執行時,可以有適配的Data Layout進行計算。
張量計算優化
張量計算優化是針對硬體特性進行多執行續的平行化(Parallelization)、計算的向量化(Vectorization)、依據Shared Memory與Cache的記憶體架構進行執行續分配與分割每次給晶片的計算量藉以增加Cache Locality及運算之間的記憶體複用率,這種優化必須針對硬體特性進行張量計算的程式重整,讓每次運算可以提高計算核心使用率與運算之間的記憶體複用率,例如迴圈轉換以迴圈切割(Tiling)、迴圈重排序(Reorder)、迴圈循環展開(Unrolling)、迴圈合併(Loop Fusion)的重整方式,將迴圈整理成適合AI晶片每次運算量的組合,提高計算效率。TVM引用了Halide的方法將演算法與排程(Compute/Schedule)分開表示,如圖3中的演算法定義了矩陣相乘運算C=AB,而同樣的矩陣相乘定義下卻可以有各種不同的排程優化選項,這必須是對硬體架構與深度學習演算法2部分都熟悉的工程師才能有效寫出優化的排程程式,讓程式在硬體上的執行效能達到最佳化,未來如TVM的使用者可共享各種硬體的優化演算法範例,將有機會讓一般工程師也可修改適用到不同公司但類似的硬體平台。
圖3 張量優化的搜索空間非常龐大,如何找到最佳的Schedule面臨挑戰[5]
TVM除了提供編譯器開發者以手動方式撰寫程式進行優化,也提出了基於深度學習的自動優化搜索(Auto-Tuning)機制,透過自動化方式找出最適合目標硬體執行的排程(如圖4)。TVM自動優化搜索機制,設計了排程探索(Schedule Explorer)用於產生所有可能會有性能提升的程式碼,然後用一個基於機器學習的評估模型(Cost Model)來預測這個程式碼的效能(TVM以高效率執行當作探索目標),這樣不斷迭代搜索,直到得到一個最佳化的排程結果。
圖4 TVM除了手動張量優化,也提供基於深度學習的自動優化機制[5]
TVM深度學習編譯器的展望
TVM社群是一個深度學習編譯技術的開放性討論社群,國際上知名的晶片軟硬體大廠都是成員[9],包含:Intel、ARM、Qualcomm、AMD、NVidia、Xilinx、Amazon、Facebook、Microsoft等,頂尖學術機構如康乃爾大學、華盛頓大學、柏克萊大學、卡內基美隆大學、加州大學洛杉磯分校等也是參與TVM發展的重要成員,TVM於2018年發表的論文[4]短短2年之間已被引用超過300次,可見TVM對於深度學習編譯技術的重要地位。工研院資通所也是TVM社群的成員之一,積極協助晶片業者開發支援AI晶片的深度學習編譯器,如圖5所示,工研院開發了支援微型無作業系統硬體的深度學習編譯技術,也開發TVM編譯流程支援整合RISCV CPU與AI晶片的模擬器(ESL),更與國際大廠合作研發多核心異質晶片的深度學習編譯技術。工研院深度學習編譯技術團隊將持續研究微型化設備的編譯技術、自動優化排程探索、支援異質多核心編譯推論、多模型編譯等議題。
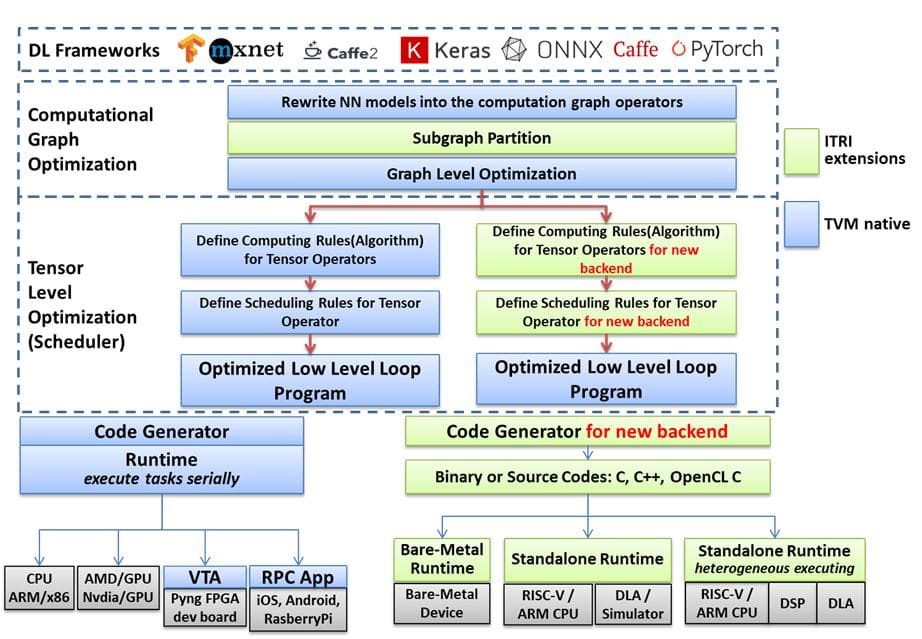
圖5 工研院協助業者開發的深度學習編譯技術
結論
TVM提出了一個端到端的深度學習編譯軟體架構,以解決跨多種硬體後端的深度學習編譯優化挑戰,TVM的架構彈性高,在各種產出的效能評比上都有傑出的表現,但如要修改其內部程式適用到不同平台,仍有一定的複雜度和門檻,工研院資通所深度學習編譯技術團隊具有各種異質晶片編譯工具開發經驗,可提供技術服務。TVM受到各方的重視,許多國際團隊皆視為主要編譯開發的平台,也因此更新速度快,我們應持續了解其開發重點,才能發揮開源合作的好處。TVM在未來有幾項重點工作正在進行中,如計算圖分割的共同框架,量化運算子支援,更有效的排程探索方法等,需要更多方投入開發,我們知道深度學習編譯軟體是一個需要軟體工程師、韌體工程師、硬體工程師、AI工程師等共同合作方能完成的工作,也是具備高度專業化的開發任務;TVM提出自動化端到端優化的編譯機制,降低TVM支援不同硬體的開發門檻,如能掌握其關鍵技術,對於AI系統的推廣和應用將有非常大的助益。
參考文獻
[1]T. Q. Chen, et al., MXNet: A flexible and efficient machine learning library for heterogeneous distributed systems. In Neural Information Processing Systems, Workshop on Machine Learning Systems (LearningSys’15) (2015).
[2]M. Abadi, et al., Tensorflow: A system for large-scale machine learning. In 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16) (2016), pp. 265–283.
[3]A. Agarwal, et al., An introduction to computational networks and the computational network toolkit. Tech. Rep. MSR-TR-2014-112, August 2014.
[4]T. Q. Chen, et al., TVM: An Automated End-to-End Optimizing Compiler for Deep Learning, the Proceedings of the 3th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’18), p.579-594, October 8–10, 2018.
[5](2018) T. Q. Chen, TVM Stack Overview, TVM Conference 2018 [Online]. Available: https://sampl.cs.washington.edu/tvmconf/2018
[6]N. Rotem, J. Fix, S. Abdulrasool, et al. (2019) Glow: Graph Lowering Compiler Techniques for Neural Networks [Online]. Available: https://arxiv.org/abs/1805.00907
[7]C. Scott, K. B. Arjun, B. Anahita, et al. (2018) Intel nGraph: An Intermediate Representation, Compiler, and Executor for Deep Learning [Online]. Available: https://arxiv.org/abs/1801.08058
[8]Jonathan Ragan-Kelley, et al., Halide: a language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines, Proceedings of the 34th ACM SIGPLAN Conference on Programming Language Design and Implementation, June 2013, p.519–530.
[9] (2020) Organizations using and contributing to TVM [Online]. Available: https://tvm.apache.org/community
[10] (2020) Frontends for constructing Relay programs [Online]. Available: https://tvm.apache.org/docs/api/python/relay/frontend.html