工業技術研究院 資訊與通訊研究所 盧峙丞、鍾喬登、鄭桂忠、莊凱翔
AI浪潮來臨!準備好了嗎?
在過去的10年裡,由於處理器速度的提高和大數據的出現,使得深度學習演算法(Deep Neural Network, DNN)的技術快速進展,並在許多領域中都取得了突破性的進展,最為突出的莫過於影像分類(Classification)、目標分類與定位(Classification+Localization)、目標檢測(Object Detection)、場景分割(Segmentation)等(圖1),甚至超越人類的辨識準確度,而代價則是引入了極為龐大的運算量,對裝置端硬體系統實現增加了2個新的挑戰:即時操作(Real Time)和低功耗(Low Power)。因此,在邊緣裝置系統中,我們會需要高精準度,又要有低運算量的操作,為了達成此目的,便有許多有別於以往的設計思維產生。
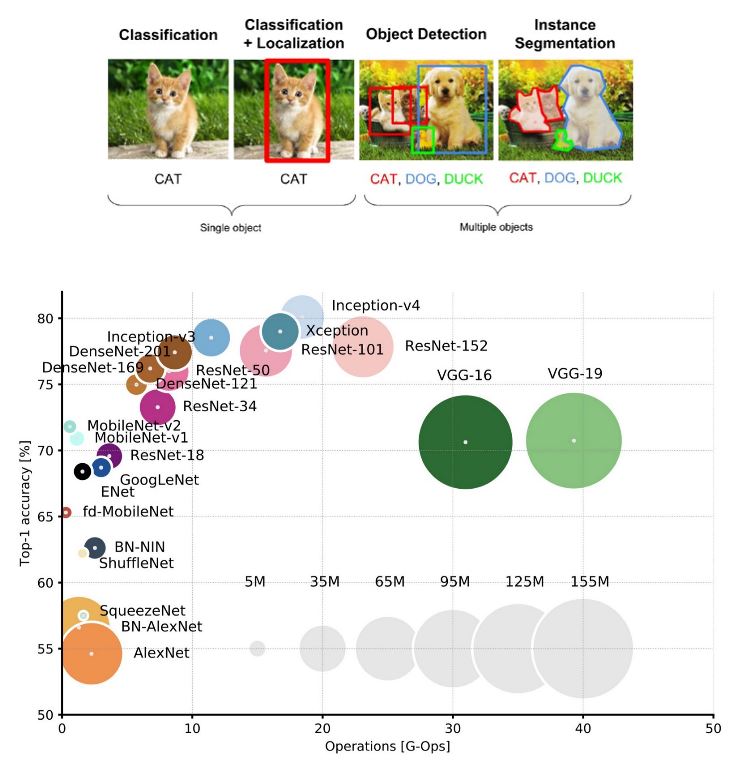
圖1 深度學習演算法發展趨勢
精彩內容
- AI浪潮來臨!準備好了嗎?
- 階層式運算架構
- 軟硬兼施的AI晶片系統將成為主流
AI趨勢雲端走向裝置端
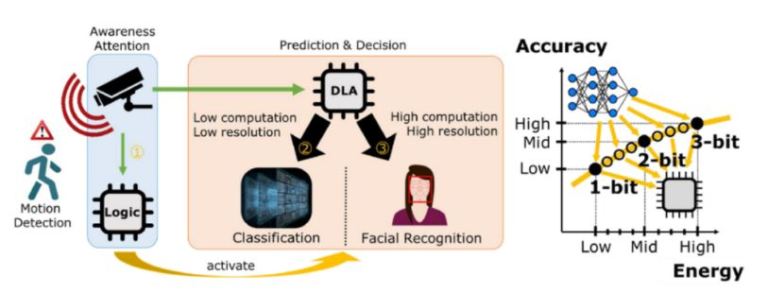
圖2 智慧物聯網裝置系統概念圖
傳統的物聯網裝置概念是將數據從本地設備發送到雲端進行處理。一些人對這個概念提出了一定的擔憂:包括隱私、延遲、儲存和效能等等。為了在邊緣裝置上執行深度學習演算法,開發低功耗、低延遲的深度學習加速器(Deep learning accelerator, DLA)以實現智慧物聯網(AIoT)裝置系統(圖2)已成為設計考量的重點,而不同場景有其不同客製化的需求(圖3)舉例來說,Face ID應用有隱私性的需求,自駕車系統需要即時性的偵測與危險的預知能力,智慧穿戴裝置可以針對使用者的EEG/PPG等訊號做偵測,但又要保有醫療上的隱私性,且資料都要有一定的可靠性,此外,包含智能眼鏡、空拍機與智慧音箱……,都已經開始朝向客製化晶片(Application Specified Integrated Circuit, ASIC)的設計,但隨著資料量與運算需求的增長,硬體上如何做有效的配置將會成為客製化晶片所需解決與探討的問題。

圖3 智慧物聯網的特點
硬體運算效能限制
由於演算法的發展趨勢伴隨著硬體上運算量和記憶體容量不斷增加,透過「將資料於處理器和記憶體之間傳輸處理」的傳統凡紐曼架構(von Neumann Architecture),不僅會限制其速度、更會消耗額外的功耗,而運算效能也會根據記憶體傳輸頻寬與硬體運算力配置有其極限(圖4)。
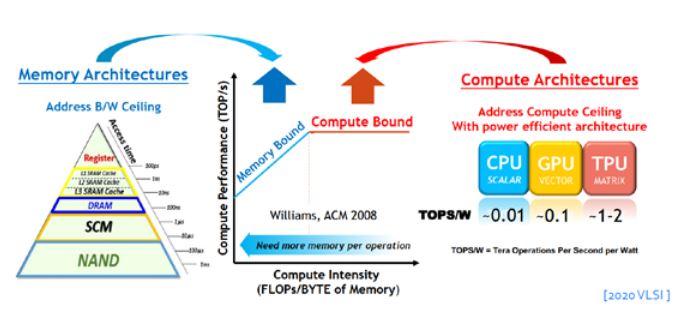
圖4 硬體運算限制
因此,為了提升資料傳輸速度並減少功率消耗,國內外團隊開始研發多種新型系統架構,從記憶體階層配置到運算架構的設計,在邊緣裝置中執行人工智慧運算已成為研究的新興課題。此外,感測器(Sensor)與記憶體(Memory)之間的偕同運算架構將不是唯一,在功耗效能(Energy Efficiency)與資料處理的彈性(Signal Processing Flexibility)考量下,將會有百花爭鳴的架構提出,以因應客製化需求來做最好的系統設計。(圖5)
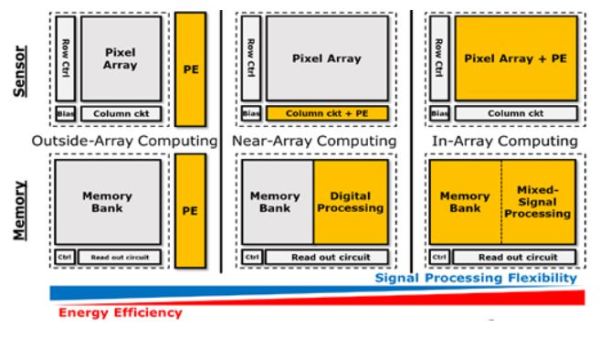
圖5 運算架構比較
階層式運算架構
階層式運算架構的概念因應被提出,簡易來說,當系統裝置不操作時維持低功耗的狀態,隨著有特徵訊號出現,再交由後端處理,如沒有特徵訊號出現將恢復為原來狀態,依此,階層式的運算架構主要就是靠2個面向來達成,感測器內處理(Processing-in-Sensor, PIS)與記憶體內運算(Computing-in-Memory, CIM)。PIS本身就有可以降低數據傳輸量與超低功耗的好處,而CIM則可減少記憶體之間的傳輸與資料間的移動。階層式運算架構便是以感測器內處理(PIS)、搭配記憶體內運算(CIM),來達成超低功耗(Ultra-low Power, ULP)的智慧物聯網裝置。類似這種概念的提出將可廣泛的應用在裝置端的硬體設計上(圖6)。
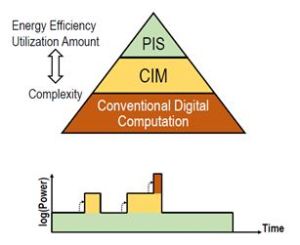
圖6 階層式運算結構
感測器內處理(PIS)
本小節說明為什麼有感測器內處理(PIS)的必要性,首先來看傳統影像感測器的幾個特點,都將會與未來資料爆炸時代相違背。(圖7)第一、固定高解析度的處理;第二、高解析度的資料轉換;第三、需要高容量的記憶體儲存;第四、高複雜度的影像處理單元。以上這4點都會慢慢走到瓶頸,就是因為如此,才有了PIS的概念產生。
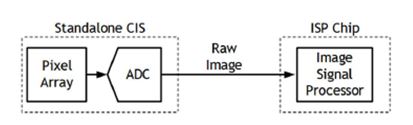
圖7 傳統CIS架構
影像感測器搭配內處理(PIS)功能架構的特點(圖8),第一、可以高速的對於特徵訊號擷取;第二、解析度可以有效降低;第三、可以達成低頻寬、低延遲、低功耗。
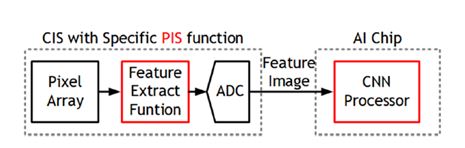
圖8 新型CIS搭配PIS架構
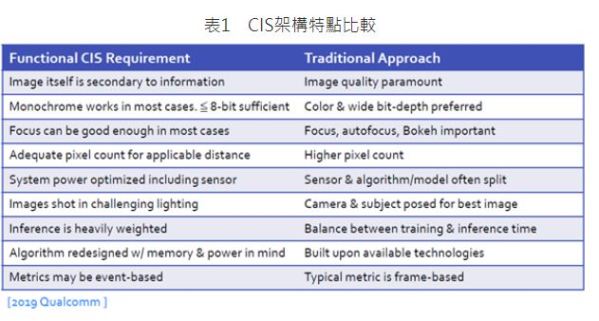
綜觀以上3點將是未來在裝置端上的特點,PIS的概念主要是針對高解析運算的前運算,聚焦於預先偵測與影像濾除等部分著手。先運算出特定影像的前處理結果、再透過後端使用者做更高解析度的演算,便能以即時的速度將資料壓縮、減少資料移動進而僅傳輸運算結果。來達成有效降低資料量、功耗和數據的延遲時間,從2019年Qualcomm所提出的比較表就可以得知,在CIS架構上有許多特點,肯定會需要改變與創新才能去適應AIoT時代的到來。(表1)
記憶體內運算(CIM)
「低延遲」與「乘累加運算(Multiply Accumulate, MAC)的功率消耗」,是當前邊緣裝置2個關鍵挑戰,CIM架構的提出就是要滿足以上要求;以CIM架構來執行MAC的操作,此處理方法在揮發性與非揮發性的CIM架構中,都可以將二進制擴展到多位元的MAC操作。在此概念下,搭配軟體與硬體的共同設計、簡化演算法運算,以克服傳統思維上的設計瓶頸。(圖9)
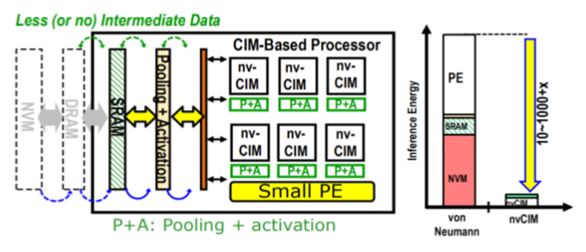
圖9 CIM概念
儘管以CIM為基礎之硬體加速器能夠克服以上特點,但是在設計CIM上還是會遇到許多挑戰,第一、CIM必須要考量軟體與硬體的共同設計;第二、類比數位轉換器與數位類比轉換器,將會增加功率消耗與面積;第三、電阻壓降(IR Drop)以及位元線(Bit Line)上面的電容會限制矩陣的儲存量;第四、記憶體元件的變異性。這在未來肯定是發展團隊上需要去突破的設計重點。
軟硬兼施的AI晶片系統將成為主流
有鑑於感測器內處理(PIS)與記憶體內運算(CIM)在超低功率消耗與資料處理上所占的優勢、加上搭配應用於神經網路(DNN)加速器(DLA)的異質運算架構,可適當的配置,「軟硬兼施」達到效能的最佳化。簡單的說,PIS與CIM可在特定場域中擷取有用且低解析度低影像大小的資料,大量減少後端AI運算之資料量。最後,下一代的AI晶片將著重在以下3點:(一)軟硬體複雜度、(二)優化資料傳輸、 (三)感測器和處理器之間的系統評估,這也是每個團隊在設計端必須面對的課題,方能確保在AI的浪頭上持續精進。最後,工研院在此領域初期以低功耗且能效大於20TOPs/W之SRAM型態之CIM為發展目標,首先建立端對端之高階效能評估模擬解決方案,提供客製化晶片之硬體設計參考,進一步往高性能並支援更多通用AI運算之CIM晶片發展。
參考文獻
[1] Alfredo Canziani, et al., “Evaluation of Neural Network Architectures for Embedded Systems,” ISCAS,2017.
[2] Kea-Tiong Tang, et al., “Considerations of Integrating Computing-In-Memory and Processing-In-Sensor into Convolutional Neural Network Accelerators for Low-Power Edge Devices,” VLSI,2019.