工研院資通所 江滄明 陽鳴谷
上網時如有「卡卡」的感覺時要怎麼辦?是網路問題還是後端平台問題?也許不是基礎架構設施的問題而是應用軟體的問題?應用效能管理系統就是來幫忙維運者找到問題的根源與解決之道。應用效能管理系統從終端使用者、網路、到後端平台,分析可能的執行路徑軌跡和各網段之延遲。Amazon估計每0.1秒的延遲,將損失大約1%的銷售額,以目前Amazon年銷售來說,這相當於年損失300多億台幣。即時快速找出問題的根源,並提出解決的方法是應用效能管理系統未來的發展方向。
Gartner將應用效能管理系統分成終端使用者體驗監控(end-user experience monitoring),應用架構模式發掘與顯示(runtime application architecture discovery modeling and display),用戶自訂交易事件解析(user-defined transaction profiling),應用元件深入管控(component deep-dive monitoring in application context),以及分析(analytics)五個面向 [1] 。Gartner APM Magic Quadrant 也都以新興公司Dynatrace、 AppDynamics、New Relic為領導廠商 [2] ,代表APM是一個新的產業機會。 IDC以自動化軟體品管(Automated software quality),網路管理(Network management),事件管理(Event management),以及效能管理(Performance management) 解析應用效能管理系統的功能與市場規模 [3] 。 如下圖所示,全球2016應用效能管理系統市場規模約34.6億美金(圖示單位是百萬美金),並預期將以CAGR 12.5%的年成長率擴大為2020年的55億美金。其中又以效能管理(Performance management)為主要成長動能。
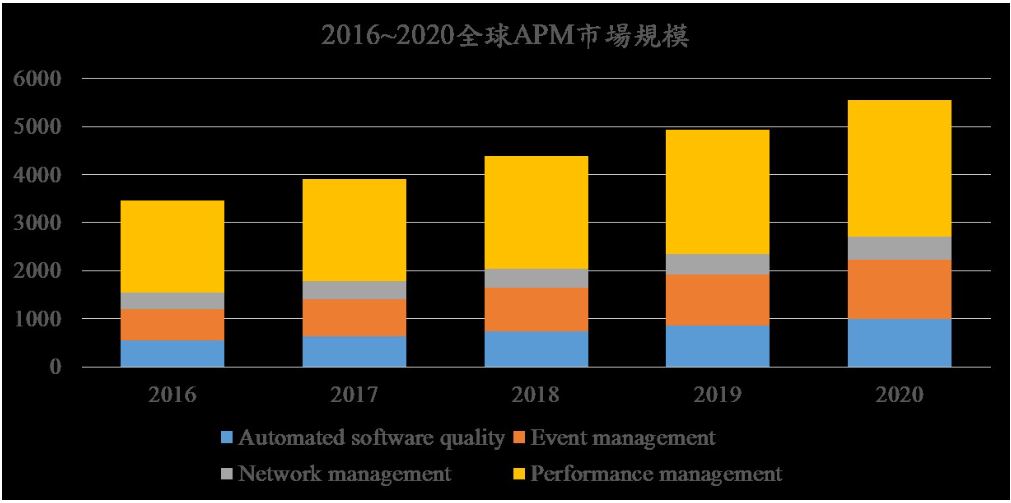
圖一:全球2016應用效能管理系統市場規模約34.6億美金
為應付多變與大量使用者的需求,大多現代軟體都採分散式結構,而應用效能管理系統主要是以儘量不改變既有應用軟體和其執行環境為首選,一般應用效能管理系統布署必須先安裝代理程式,不但費時費事,代理程式的管理在大型資料中心也是一個問題,有些效能管理系統也會更改應用軟體以安插效能或功能探針。
常見APM系統的作法
以Prometheus[4]與Jaeger[5]開源方案為例,核心概念利用變更後的程式庫擷取應用程式行為,如以下圖二所示:
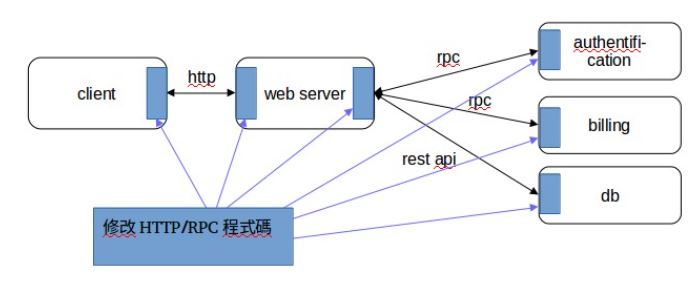
Prometheus由SoundCloud提出,是Cloud Native Computing Foundation計畫之一,目前提供Go/Java/Python/Ruby等語言程式庫給使用者整合於應用程式碼中,以便提取各類量測指標(metrics)[6],進而提供其他服務功能,如Alert等。Jaeger由Uber提出,提供Go/Java/Python/Node等語言程式庫,採用OpenTracing時間序列的資料格式[7]。採用這些APM方案的應用程式必須修改程式碼以便呼叫程式庫,無論修改幅度大小,從資料中心維運與系統穩定角度而言都是明顯負擔,也形成運作上的核心考量與障礙。
ITRI APM的作法
工研院資通所自主開發應用軟體監控專利技術,將應用效能管理系統結合OpenStack KVM(Kernel Virtual Machine)虛擬機管理功能,免安裝代理程式,也無需改變任一行應用軟體。完全零布署時間零維護與適用無原始程式碼的應用軟體是兩大特色,並已獲得國內外廠商積極進行合作整合計畫。ITRI APM技術主要分為四步驟:
- 在虛擬機數據封包發送系統呼叫時攔截操作系統呼叫(Intercept guest OS system call at packet sending system call)
- 執行虛擬機內視以獲取運行的線程和TCP連接資訊。將這些訊息發送到流量日誌伺服器(Perform VM introspection to get running thread and TCP connection information. Send this traffic log to server)
- 將線程的訊息轉換為APM(應用效能管理)伺服器中的線程相互間流量日誌(Convert thread based traffic log into inter-thread traffic log in APM(Application Performance Management) server)
- 從線程相互間流量日誌生成準確的應用依賴關係圖(Generate accurate application dependency graph from inter-thread traffic logs)
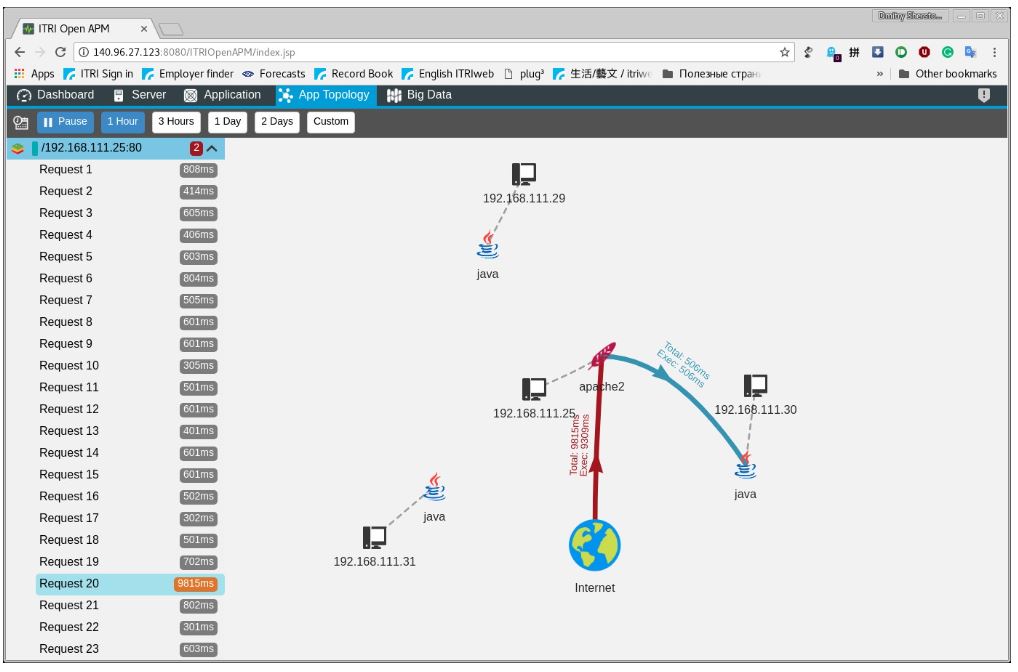
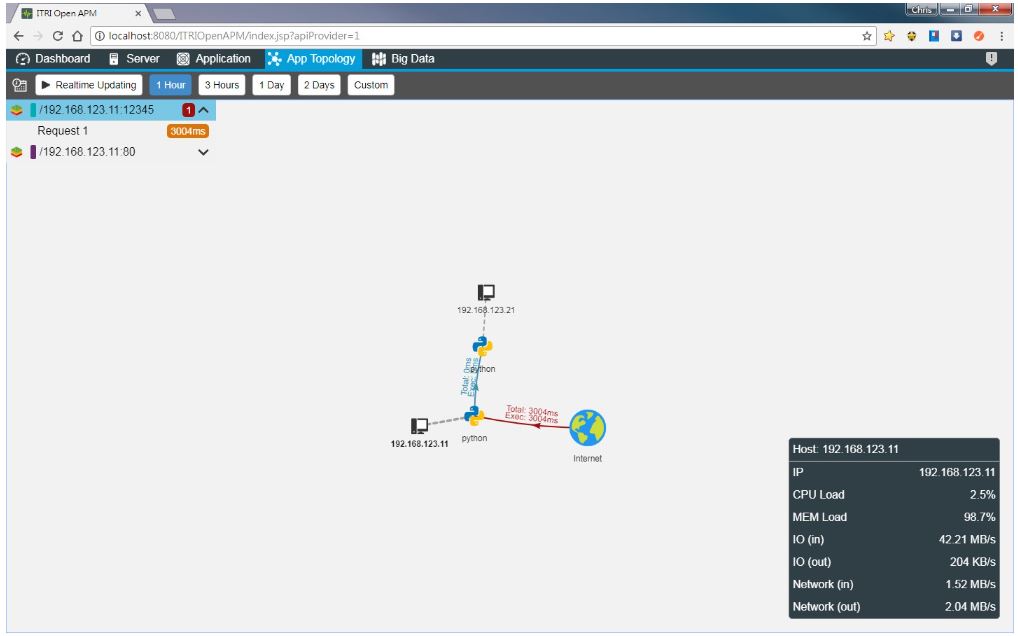
如下圖所示,ITRI APM可以發掘應用程式系統的拓樸結構與即時的系統內各功能單位之間執行HTTP/TCP呼叫與回覆(Request/Response)的實際封包路徑軌跡(Trajectory)與各網段之間的延遲(Delay),並以紅色線標示出不正常的延遲網段,讓系統維運者可以迅速確實掌握各應用程式的運作狀態。
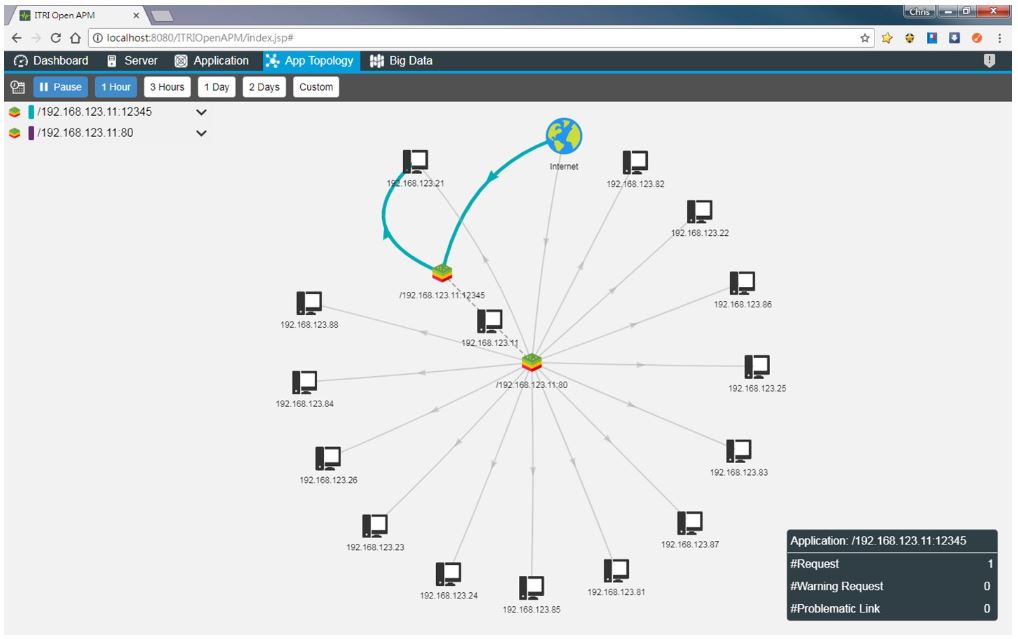
除了應用於插口(Socket Based)型態的系統以外,ITRI APM可以監督與管理信息佇列(Message-Queue Based)型態的應用系統行為。兩種型態系統如下圖所示
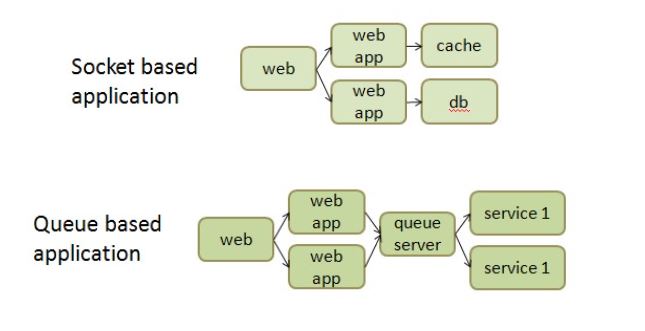
信息佇列應用系統將HTTP路徑切割成數個子系統,彼此以非同步結構連結。常見APM處理方式包括修改Java虛擬機執行碼(JVM Byte-Code Instrumentation)與修改佇列伺服器運行碼(Source-Code Instrumentation)等,除了容易造成系統的額外負擔,更將影響系統維運上的困擾,包括穩定性與系統升級等。ITRI APM採用的專利架構將達到三個層面效果:
– 不須修改既有運行軟體
– Thread-Level精準度
– Wire-Protocol信息追蹤
APM問題根源分析(Root-Cause Analysis,RCA)
在系統運行中,找出不正常延遲是一門大學問,除傳統統計方法外,人工智慧(Artificial Intelligence,AI)機器學習(Machine Learning,ML)的導入是一個新的方向,尤其是無監督式(unsupervised)自動學習[8],最適合現代即時複雜多變動的網路與軟體環境,目前設定單一靜態觸發點(threshold)的使用已不切實際,因為太多的誤判和警訊反而造成系統管理者的困擾。機器學習能根據過去的資料自動找出特徵並建立預測模型,並以此模型為偵測不正常行為的基礎。經由不斷的調整與學習,能自動適應外在條件變遷,降低錯誤偵測的警訊,以減低管理者的負擔,改善使用者的體驗和整體系統的效能。
延遲可能是因為負載增加,執行環境改變,也可能是資源不足。不正常延遲總是有原因的,找出問題的根源需要更多的訊息,包括系統資源、網路資源、設備的事件記錄、使用者行為和應用軟體的執行環境。開源軟體有很多選擇來管理和監控系統資源,ITRI APM運用開源技術,如Prometheus,主要基於其強大的時序資料庫與詢問語言介面,Prometheus在資源監控也有完整的生態環境(Ecosystem),各類開源的Exporter由3rd Party廠商提供而共同建構出豐富的應用方案體系。如下圖紅色線標示出不正常的網段可再深入分析是那一個設備或那一種軟體所造成的。
RCA概略分為四個層面:
– 商業服務層(Business Service Level)
將效能管理的各層面元器件(Monitored Components)群組對應到每個商業活動項目, 如概念到產品(Concept To Product), 產品到上線(Product To Launch), 下單到進帳(Order To Cash), 需求到服務(Request To Service), 設計到建構(Design To Build), 建構到下單(Build To Order)等,並且找出各元器件可能對服務項目的衝擊指數,依此逐項向下探尋問題根源。
– 應用層(Application Level)
分析應用程式間的反應時間快慢,如Latency,Round-Trip Time,Server Response Time等。
– 網路連接層(Network Connectivity Level)
找出網路設備間的連接性,包括埠(Port)的使用、路由表,與設備設定等資訊,確定網路連接層關係。
– 裝置設備層(Device Level)
系統的最底層硬體設備,包括伺服器、儲存設備、交換器等。除了了解其開關狀態,也能確定是否操作正常,包括CPU、記憶體、磁碟空間等狀態。
要深入分析是哪一個設備或那一種軟體造成的延遲,必須深層了解網路架構和軟體行為。網路架構的整合是建立在資通所雲端基礎設施既有的研發能量,了解軟體行為則引用應用層Deep Packet Inspection(DPI) Qosmos商業模組 [9]或開源模組 CapAnalysis[10]。DPI對網路封包進行分類與分析,這些資訊將有助於提升對在系統中執行的應用軟體之透明度,進而解析出是設備或軟體所造成的問題。
找出問題的根源,還要提出解決的療法,在這大電商時代,能即時解決問題是必要條件,actionable alarm 不只提供警示訊息,也提出解決方案,更進一步自我療癒(self-healing)也是現代先進APM的功能之一,即時自我修復或隔離問題,可將傷害減至最低。
預防勝於治療,延遲代表損失,應用效能管理已從被動式監測進化成主動式預測性應用效能管理系統(Proactive & Predictive APM),AI機器學習的導入更提升其應變能力,與網路架構與基礎設施的整合也是必然趨勢,未來幾年全球市場規模也以穩定成長,是一不容忽視的技術和產業機會。
APM未來的發展方向
專家預估2017年APM將聚焦幾個發展方向:
– 資料分析(Data Analytics)與機器學習(Machine-Learning)技術結合 :隨著應用程式與彼此連結複雜度的增加,量測指標的數量與量測資料將快速累加,如何運用愈趨成熟的機器學習與大數據技術,即時進行資料分析運算,從中篩選轉換出有價值的資訊,一方面作為問題根源的追蹤分析(Root Cause Analysis,RCA)參考,也將提供系統行為預估的方向依據。
– 全堆疊透視(Full-Stack Visibility):從應用層到基礎設施層層層具到的通透管理任務,效能監控範圍涵蓋軟體,虛擬服務與硬體諸多面向。
– 物聯網(IoT)應用:大數據應用系統的效能監控與管理將是新的課題。
– 混合雲與多雲(Hybric-Cloud & Multi-Cloud)應用:APM需要提供跨越雲界線方案。
– 微服務(Microservices)與容器(Containers)應用:服務微型化輕盈化的應用將加速發展,APM系統必須因應趨勢提供新的技術與工具。
– 開源軟體(Open-Source Software, OSS):軟體開源將為APM打開寬廣視野,也將是效能管理技術躍進的重要推手。APM相關規格與技術規範也將藉由開源技術逐步統合,進而推升相關標準的訂定。
因應未來新的技術挑戰,工研院資通所將持續精進APM相關技術,結合技術研發、系統整合、市場開發等各面向夥伴們,發揮綜效合力耕耘此日益關鍵蓬勃發展的資訊應用領域,並以合適方向內容實際回饋國際世界的開源社群,累積台灣開源技術能量。
參考文獻
[1] http://www.gartner.com/it-glossary/application-performance-monitoring-apm
[2] https://www.gartner.com/doc/3551918/magic-quadrant-application-performance-monitoring
[3] https://www.idc.com/getdoc.jsp?containerId=US40936416
[4] https://prometheus.io/docs/instrumenting/clientlibs/
[5] http://jaeger.readthedocs.io/en/latest/
[6] https://prometheus.io/docs/concepts/metric_types/
[7] http://opentracing.io/
[8] http://www.sciencedirect.com/science/article/pii/S0925231217309864
[9] http://www.qosmos.com/
[10] http://www.capanalysis.net/ca/